연구소
연구 배경
- 온라인상의 뉴스와 SNS 게시물은 데이터를 수집하고 처리, 분석하는 내용이 유사한 경우가 많습니다.
- 내용은 텍스트, 이미지, 동영상, 여러 링크가 있습니다. 그 중에서도 자연어(Natural language) 처리 기술이 발전하면서 텍스트 유사도는 자연어 처리 기술과 결합하여 더욱 정확하고 효율적인 분석을 가능하게 해주고 있습니다.
- 텍스트 유사도의 장점을 활용하여 학습 데이터 수집 및 분석과 이를 통한 맞춤형 콘텐츠 제공에 힘쓰고 있습니다.
- 굿모니터링 주식회사는 뉴스와 SNS 사이의 텍스트 유사도를 측정 및 비교, 분석하고 있습니다.
측정 도구
-
코사인 유사도(Cosine similarity)
두 벡터(Vector) 간 코사인 각도를 이용해 유사도를 측정하는 방법으로 텍스트 데이터나 문서 간의 유사성을 계산하는 데 자주 사용됩니다.
유사도 측정값이 ‘1’에 가까울수록 벡터 간의 유사성이 높다고 판단되고, ‘0’에 가까울수록 유사성이 낮아집니다.
(※ 측정값이 음수일 경우 두 벡터가 반대 방향을 가리키고 있다는 것을 의미함)
※ 출처 : 구글(Google)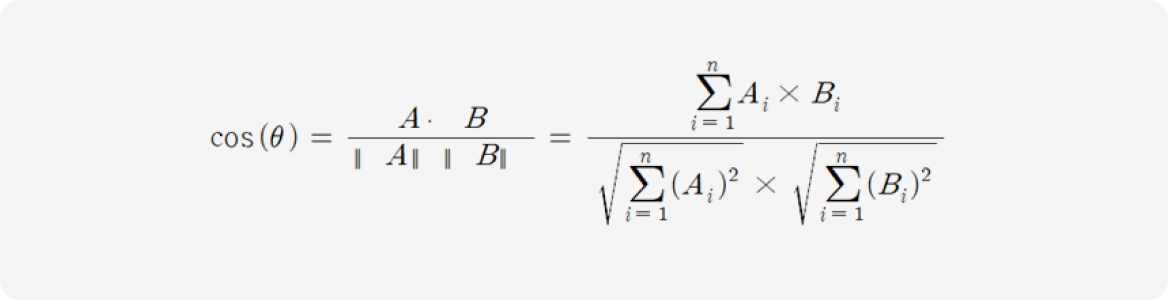 ※ 출처 : 구글(Google)
※ 출처 : 구글(Google)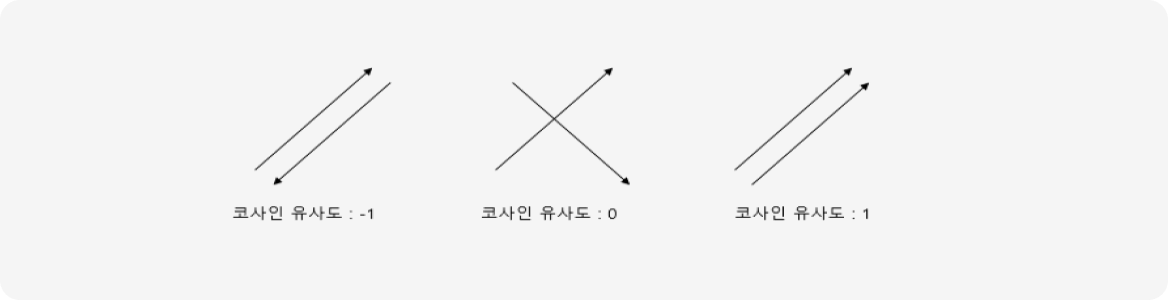
-
자카드 유사도(Jaccard similarity)
두 집합(Set) 사이의 유사도를 측정하는 방법 중 하나로, 두 집합의 교집합(Intersection) 크기를 합집합(Union) 크기로 나눠 계산합니다.
‘0’과 ‘1’사이의 값을 가지며, 두 집합이 동일하면 ‘1’의 값을 가지고 공통 원소가 하나도 없으면 ‘0’의 값을 가집니다.
※ 출처 : 구글(Google)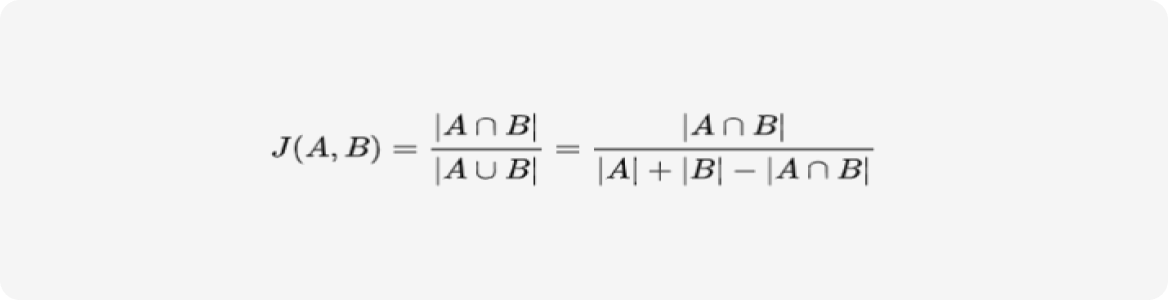 ※ 출처 : 구글(Google)
※ 출처 : 구글(Google)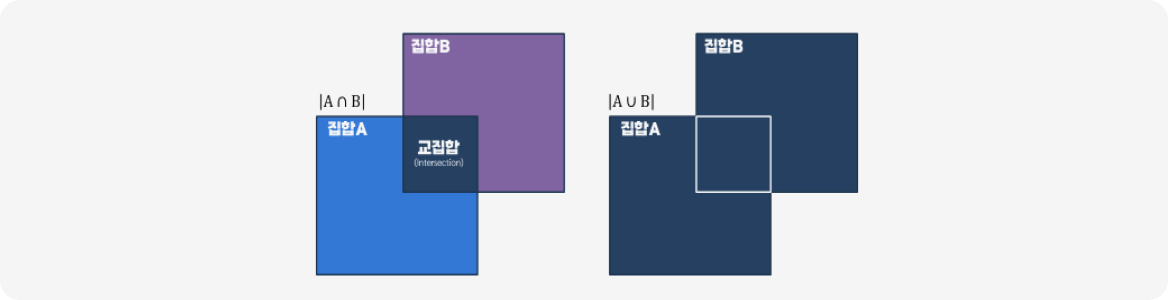
-
피어슨 유사도(Pearson similarity)
두 변수(Variable) 간의 선형 상관관계(Correlation analysis)를 측정하는 방법 중 하나입니다.
데이터 간의 상관관계를 파악하는 데 사용됩니다. 두 변수 간의 선형적인 상관관계를 측정하며, 유사도 측정값이 ‘1’에 가까울수록 양의 상관관계, ‘0’에 가까우면 선형 상관관계가 거의 없거나 매우 약한 관계입니다.
※ 출처 : 구글(Google)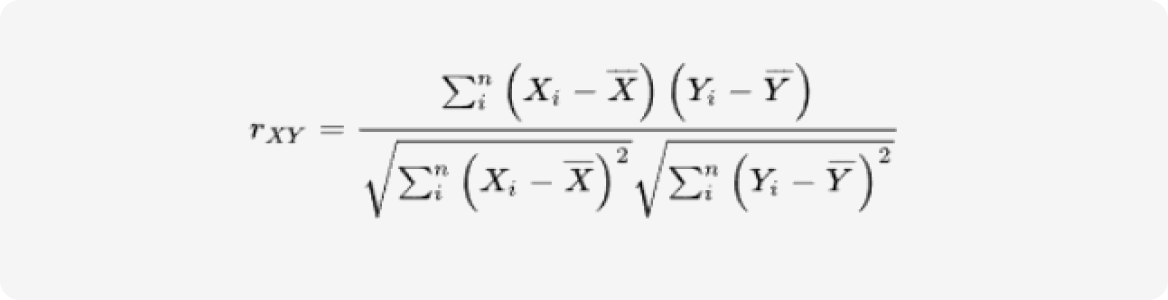 ※ 출처 : 구글(Google)
※ 출처 : 구글(Google)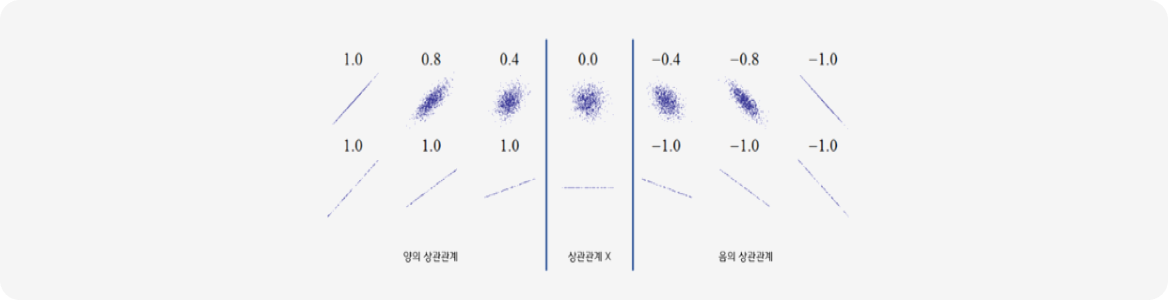
텍스트 유사도 연구 프로세스
굿모니터링 주식회사는 아래 4단계를 걸쳐 유사도 측정값을 도출합니다.-

- 데이터 추출
- 데이터 수집, 텍스트 추출, 데이터 타입 확인 및 변환
-

- 데이터 전처리
- 결측치(Missing value) 확인, 텍스트 분리 및 삭제, 불용어(Stop word) 제거
-

- 유사도 계산
- 측정 도구를 활용해 두 텍스트 간의 유사도 측정
-

- 결과 도출
- 유사도 측정값 도출, 상관관계 분석 및 데이터 시각화
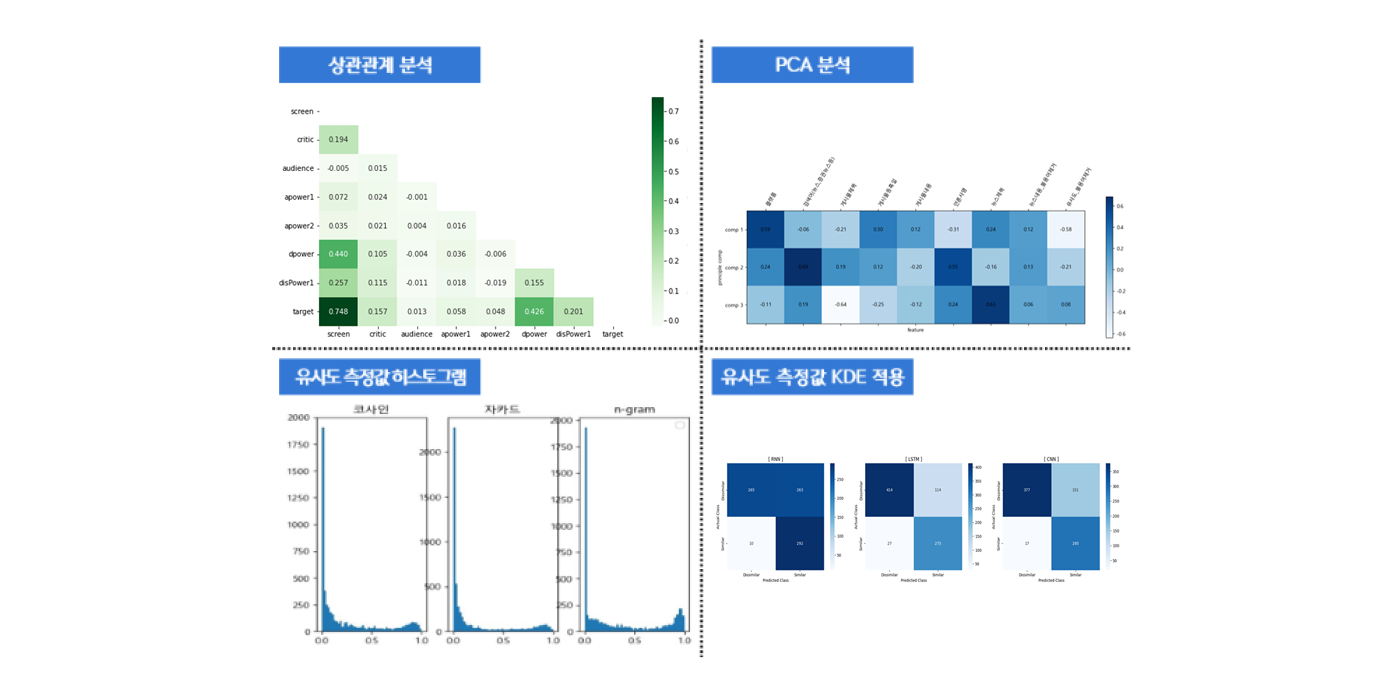
대시 보드
- [뉴스저작권 모니터링] 뉴스 원문과 복제 게시물 간의 텍스트 유사도를 비교하여 복제 비율을 산출하고, 정량적인 기준 연구